

Defining Personal Information and the Remediation Framework
In this post, we go through the research that has led to defining personal information and the resulting framework to detect and remediate personal data.


Personal Information, Personally Identifiable Information and Personal Data! What is What?
As part of our research, it was important to understand existing definitions of personal information and personally identifiable information (PII) from the standpoint of existing laws in Europe, the West, China and around the world.
In defining PII, we started with the current definition: “Information that can be used to distinguish or trace an individual's identity, either alone or when combined with other personal or identifying information that is linked or linkable to a specific individual.”
In Europe, “personal data” is the term used and is roughly equivalent to Personally identifiable information (PII) as defined in the GDPR:
Article 4(1): ‘personal data’ means any information relating to an identified or identifiable natural person (‘data subject’); an identifiable natural person is one who can be identified, directly or indirectly, in particular by reference to an identifier such as a name, an identification number, location data, an online identifier or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person.”
According to the GDPR, “protection should be extended to anything used to directly or indirectly identify a person (or data subject). This may be extended to include characteristics that describe "physical, physiological, genetic, mental, commercial, cultural, or social identity of a person."
This is a much broader definition compared to the other jurisdictions as we’ll see later. Under the GDPR personal information includes the following:
Names
Addresses
Financial information
Login IDs
Biometric identifiers
Video footage
Geographic location data
Customer loyalty histories
Social media
More recently, IP Address
HOW PERSONAL INFORMATION DIFFERS BY JURISDICTION
CHINA - Personal Information Protection Law (PIPL)
China’s Personal Information Protection Law (PIPL) defines personal data as “any kind of information relating to an identified or identifiable natural person, either electronically or otherwise recorded, but excluding information that has been anonymized.”
Definition of sensitive personal data is more readily defined as:
“Information that, once leaked or illegally used, will easily lead to infringement of human dignity or harm to the personal or property safety of a natural person, including (but not limited to): (i) biometric data; (ii) religion; (iii) specific social status; (iv) medical health information; (v) financial accounts; (vi) tracking/location information; and (vii) minors data.”
CANADA - Personal Information Protection and Electronic Documents Act (PIPEDA)
According to The Personal Information Protection and Electronic Documents Act (PIPEDA), Canadian privacy law, personal information is defined as “data about an identifiable information or information that on its own or combined with other pieces of data, can identify someone as an individual.” This is similar to the definition posed earlier. Examples of personal information in a PIPEDA context include information about an individual’s:
Race, national or ethic origin;
Religion;
Age, marital status;
Medical, education or employment history;
Financial information;
DNA;
Identifying numbers such as social insurance number or driver’s license number;
Views or opinions about that individual as an employee.
In Canada, “sensitive personal data” is not specifically defined except in the case of Quebec Privacy Act, which states, “any information that, by virtue of its nature (e.g. biometric or medical), or because of the context in which it is used or communicated, warrants a high expectation of privacy.”
UNITED STATES - California Consumer Privacy Act (CCPA) and more recently, California Rights Privacy Act (CPRA)
In the United States, privacy legislation is more fragmented at the state level, however, one of the most stringent ones is The California Consumer Privacy Act (CCPA), which more closely aligns with the GDPR. According to this law, personal information is defined as “information that identifies, relates to, describes, is reasonably capable of being associated with, or could reasonably be linked, directly or indirectly, with a particular consumer or household.”
Identifiers can include: real name, alias, postal address, unique personal identifier, online identifier, internet protocol address, email address, account name, social security number, driver’s license number, passport number, etc.
This has extended to the following:
Commercial information, including records of personal property, products or services purchased, obtained, or considered, or other purchasing or consuming histories or tendencies.
Biometric information.
Internet or other electronic network activity information, including, but not limited to browsing history, search history, and information regarding a consumer’s interaction with an internet website, application, or advertisement.
Geolocation data.
Audio, electronic, visual, thermal, olfactory, or similar information.
Professional or employment-related information.
Education information that is not publicly available but includes personally identifiable information.
“Inferences drawn from any of the information identified in this subdivision to create a profile about a consumer reflecting the consumer’s preferences, characteristics, psychological trends, predispositions, behavior, attitudes, intelligence, abilities, and aptitudes.”
The California Privacy Rights Act (CPRA), which amends the CCPA and includes privacy protections already passed from November 2020 added the definition of “sensitive personal information” as follows:
Social Security, driver’s license, state identification card or passport number
account log-in, financial account, debit card or credit card number in combination with any required security or access code, password or credentials allowing access to an account
precise geolocation
racial or origin, religious or philosophical beliefs, or union membership
contents of a consumer’s mail, email, and text messages unless the business is the intended recipient of the communication
genetic data
biometric information
health information
information about sex life or sexual orientation
To understand the varying definition levels of personal information in the United States, this reference of the State by State US Breach Notification provides guidance on the type of personal information that triggers a breach notification obligation by companies to individuals (customers, employees or stakeholders with whom they have a relationship).
In these cases, Personal Information is defined as first name, Initial and last name plus identifiers. Some of the states define these types as “personal information” even absent individual names if the information itself is sufficient to commit identity theft.
Here a few of of these state examples:

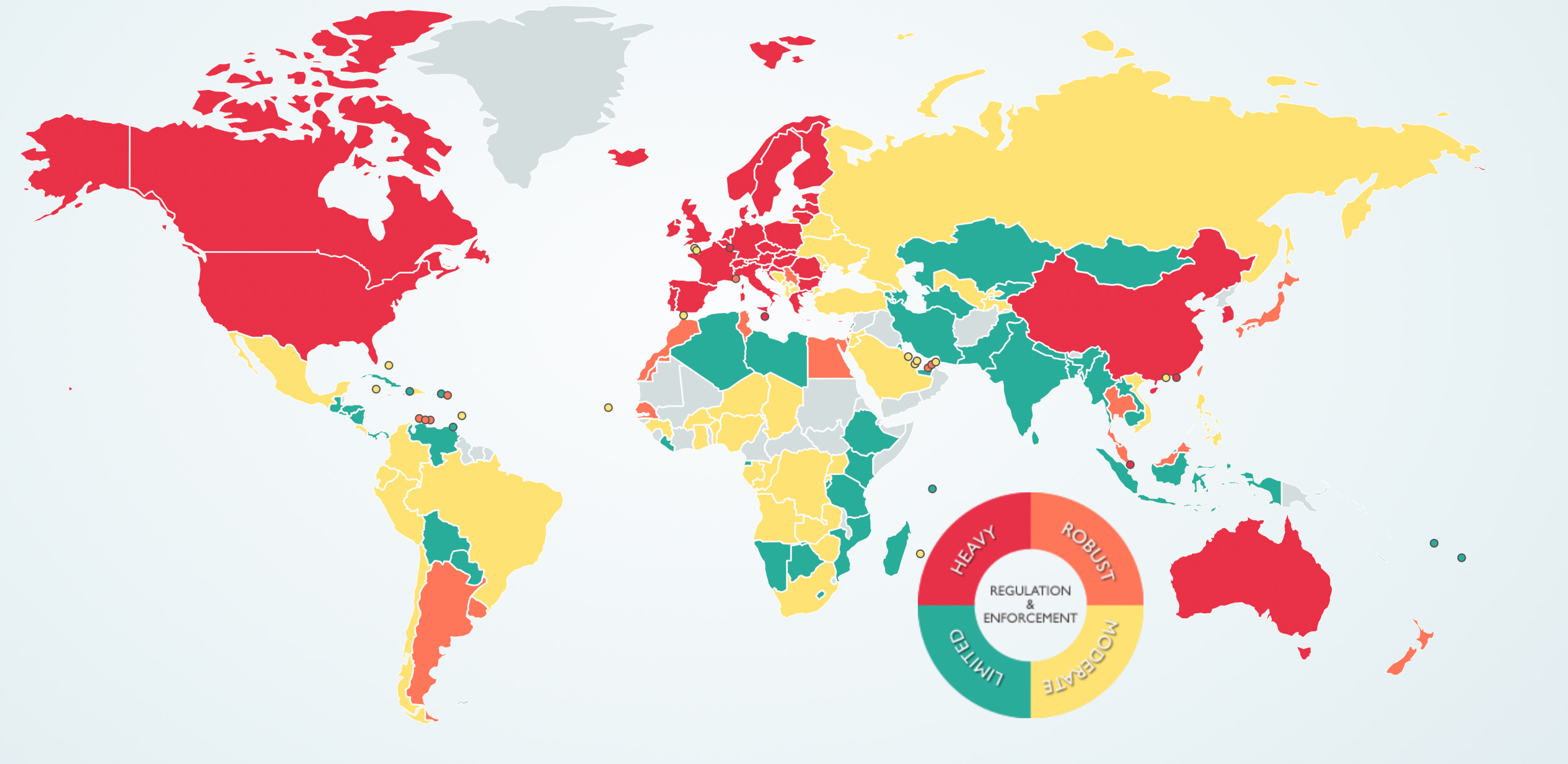
Only a handful of jurisdictions like Egypt, Morocco, Senegal, Malaysia, Thailand and Argentina come close with robust privacy laws (see orange reference in map below ) but are much less restrictive compared to the above jurisdictions: US, Canada, China, EU and Australia.
Argentina: “Personal data is defined as information of any type referred to individuals or legal entities, determined or which may be determined.”
Sensitive personal information as, “personal data which reveal racial or ethnic origin, political opinions, religious, philosophical or moral convictions, trade union affiliation and information related to health and sexual activities.”
This comparative map: Data Protection laws of the World provides a great overview of the varying levels of data protection laws globally.
THE BASIS OF RE-IDENTIFICATION
Once we understood the distinction between personal information and sensitive personal information, this formed the basis of re-identification. The latter, therefore, is based on determining the likelihood based on each piece of information on its own or in combination with another.
Personal Information comes in two varieties:
Linked information is the more sensitive variety. Anything that can by itself be used as an identifier is considered linked information. Social security numbers, driver’s license numbers, full names, and physical addresses are all examples of linked information. We will refer to this as [direct] identifiers.
Linkable information is the second category. Linkable information can’t do much on its own, but it becomes powerful when linked with other pieces of information. ZIP code, race, age range, and job information are all examples of linkable information. We will refer to this as ‘quasi’ identifiers.
PII AND SENSITIVITY
PII can also be publicly available through websites, telephone directories, that can be linked to First and last name. Typically this includes physical address, phone number and email address.
“Non-PII can become PII whenever additional information is made publicly available, in any medium and from any source, that, when combined with other available information, could be used to identify an individual’.
In order to determine what is considered the highest risk of personal information we applied sensitivity trigger with the following elements:
Degree of Sensitivity : Source: Satori Data Classification
Public
Business Sensitive
Sensitive
LOW Sensitivity Data - typically, public information that does not require access restrictions falls under this category. Other applicable areas: web pages, blog posts, public listings
MEDIUM Sensitivity Data - typically, data that is intended only for internal or private use. The trigger is if this information were exposed will this have a strong impact on the organization? Examples include: business plans, customer lists and non-identifiable personal data
HIGH Sensitivity Data - typically, restricted data is protected by regulation or compliance standards. These data require strict access controls and protection measures. The trigger is if this information were exposed, the data may cause significant harm to individuals and the organization, which may also result in compliance penalties or fines.
Note: compliance and government mandates: PCI, HIPAA, GDPR and the protection of intellectual property.
For the purpose of developing the Privacy Standards , we will focus on the HIGH Sensitivity Data.
APPROACH FOR CLASSIFYING PERSONAL INFORMATION
Note the approach we used was based on Satori Cyber Data Classification Matrix: at the data level.
S3: Data Classification (S^3)
Specificity (Identifiability)
Sensitivity
Scarcity
S4: Source or Website Classification
Specificity or identifiability: How easily can this data be used to identify an individual? - Two levels:
[direct] Identifiable e.g. driver’s license number, SSN, SIN = High Identifiability
Quasi-identifiable e.g. gender, phone, text patterns (social profiles) = Low-Medium identifiability
Sensitivity: How much damage can be done if this reached the wrong hands? The loss of, or unauthorized access to PII can result in significant harm, “embarrassment and inconvenience to individuals as well as the organization controlling the data”.
Scarcity: How readily is this data available? Typically, there is an inverse relationship between readiness and risk i.e. the more scarce the data (or the more readily available) the higher the risk.
Source: What is the “intent” of the website source i.e. to inform and create a resource for public use? This needs to be balanced with the harm in and of the data itself. In many cases, by defining the intent of the data source, we can make a quick evaluation of the risk.
As a matter of identifying the level of risk, Source categorization will be used as a first step to make an initial risk BEFORE 1, 2, 3 are applied to the data.
Caveat: while the initial intention of a data source is pre-defined, it may pose additional risks of re-identification when combined with additional data sources. Overtime, the use of each data source should be re-classified based on their usage and risk outcomes they generate.
RULES FOR SCORING
STEP 1: Risk will be applied to Source: label: low, medium, high
If risk is low, do not proceed to additional sensitivity scoring
If risk is medium to high, proceed to additional sensitivity scoring
STEP 2: Risk will be applied across S3: low, medium, high to determine remediation course
If risk across all S3 = LOW then remediation = keep data “public”
If risk across all S3 = HIGH then remediation = restrict data
If risk across all S3 = a MIXTURE of high, medium and low rankings then remediation = keep data “private”
Remediation definitions
Public = do nothing to the personal data
Restrict = Redact personal data - e.g. replace 90210 with xxxxx - so there is no determination of what xxxx equates to
Private = Pseudonymize or Anonymize personal data - e.g. replace John Smith with [John Doe] or [first name, last name]
The distinction between Restrict and Private is that "restrict" also removes what the data "means" (the PII Instance type), while "private" just removes the PII value, but leaves in place its type.
Please note, while this provides a high-level approach to classify personal information and courses of action to apply privacy remediation, this will vary jurisdiction by jurisdiction. We have simply created a framework as a starting point.
Here is an example of how this may be applied:
The Source = Business that captures User Data. User Data could be employee or customer.
The Source level = Medium to High Risk. Therefore, we begin to classify the data values based on the (S^3) Classification to determine remediation.

If you would like to participate in this open project, if you have ideas on how we can improve what we’re doing or you have access to communities who may benefit from our project please contact Hessie Jones at hessiej1228@gmail.com.