

Enhancing Privacy in Healthcare Data: Building the Foundation for PII Detection
A Trent University Collaboration Part 1 of 2: By Yukta Ambre, Manthan Patel, and Mosami Patel

Team 1
Background
In September 2024, the PIISA team engaged with the Trent University Graduate Program in Peterborough for a project designed to augment PIISA framework for personally identifiable information detection and remediation. We decided to develop projects that would focus on two domains: 1) health care data 2) customer service data.
The Purpose: The goal of PIISA is to be able to preserve personal information (PII) and limit the leakage of PII when developing language models or when data is in transit. By allowing organizations to use locally deployed open source libraries before downstream data usage, we can ensure that organizations will already limit their risk of PII exposure.
The Students’ Task: The students would work alongside our data scientists and computer science team to curate a dataset, provide documentation and guidelines on the curation and annotation process for detection and remediation.
The Scope:
Curate PII dataset for a range of generally unsupported entity types and entity linking, such as DISEASES, NORP, etc. This can be done in a mixture of manual annotation and programmatic annotation with active learning and weak (guided) supervision.
Objective 1: A curated dataset with annotated ground truth for span classification and entity relation classification,
Application domain characterization: Write guidelines for said entity types and guidelines:
determination of applicable PII entity types for each domain
draft policies for the management of those PII entity types within those application domains, possibly for different applications & roles
synthesize this information into domain-specific guidelines for the creation of datasets
Creation of seed dataset: Curate PII dataset for a range of generally unsupported entity types and entity linking:
Search for available content in the designated domains
Select appropriate dataset chunks for PII representation
Apply domain guidelines to annotate the desired outcome of an eventual PII detection and labelling model on a data subset
Data augmentation from the seed: automatic generation from the seed: Perform programmatic annotation rather than purely manual annotation.
Use Large Language Models for the creation of additional annotated dataset samples
Adapt prompt engineering techniques as needed to induce the desired model outcome
Generate as a result an order of magnitude more data
THE REPORT
By Yukta Ambre, Manthan Patel, and Mosami Patel
Healthcare is one of the most sensitive and highly targeted sectors for data breaches. Did you know that in 2023 alone, over 50 million healthcare records were compromised? That’s millions of patients whose personal data—names, medical histories, and even social security numbers—fell into the wrong hands. These breaches not only lead to identity theft and financial fraud but also shatter the trust patients place in healthcare providers.
Why is this happening? Healthcare data is a goldmine for hackers. It is valuable, sensitive, and often poorly protected. Outdated systems and manual processes are no match for modern cyber threats. But there is good news. Our project, Enhancing Privacy in Healthcare Data: Building the Foundation for PII Detection, aims to change the game.
Let’s explore how we are creating a strong solution to protect sensitive healthcare data:
Imagine going in for a routine check-up, only to find out later that your identity has been stolen because your healthcare provider’s systems were breached. It’s not just about stolen information; it’s about broken trust. Patients rely on healthcare providers to safeguard their most personal information. When that trust is violated, the consequences can be devastating. Identity theft and financial fraud are only the beginning. Patients may also hesitate to share crucial health information in the future, which weakens care quality and causes legal problems for providers. Breaking privacy laws like HIPAA in the U.S. or GDPR in Europe can result in heavy fines and legal battles. Our project works directly on these problems by creating advanced, scalable, and precise PII detection for healthcare data. The goal is to help healthcare providers innovate safely while protecting patient privacy and trust.
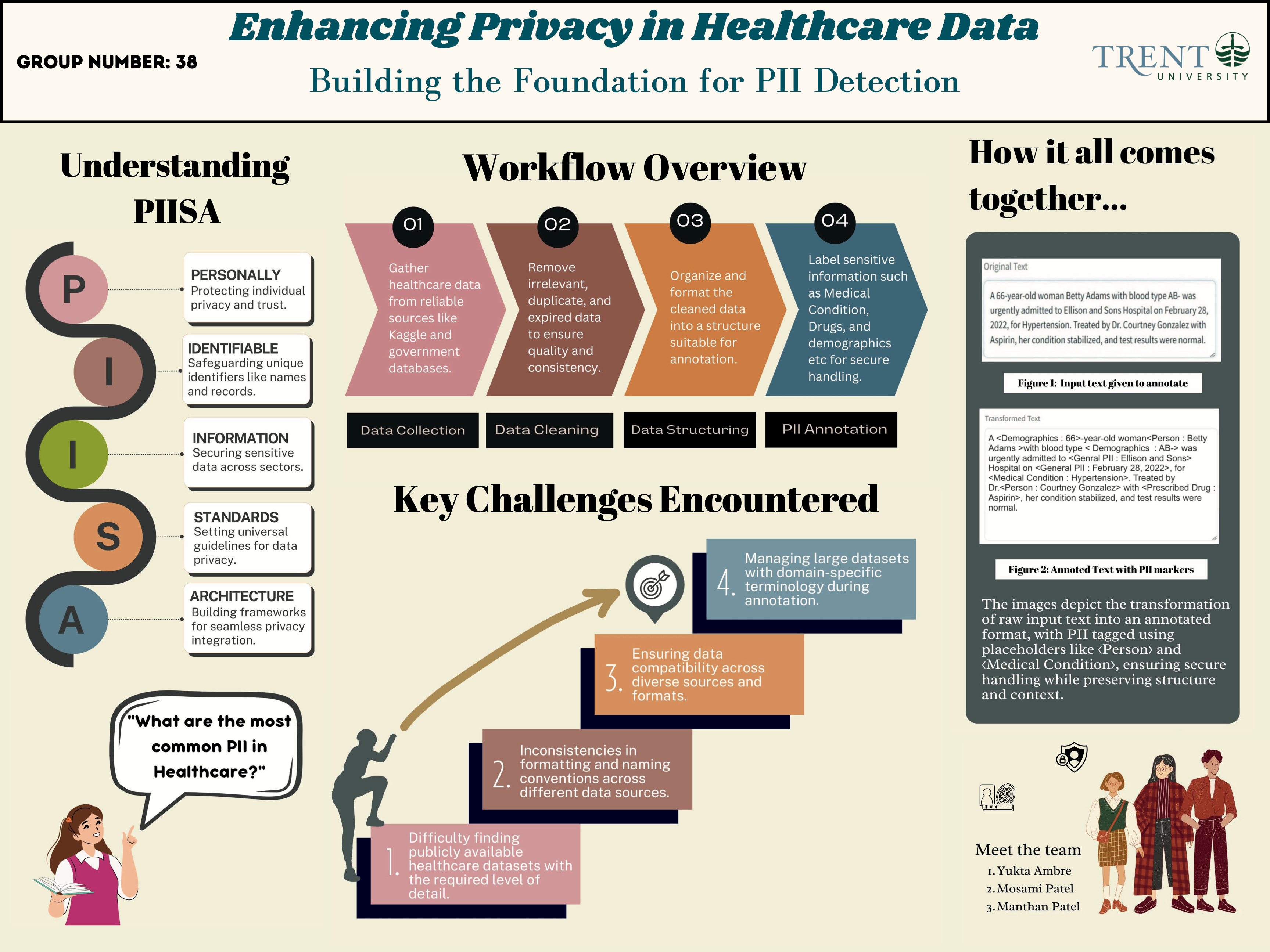
To solve the difficulties of protecting healthcare data, we created a complete, multi-step process. It started with data collection. Our team gathered over 498,000 healthcare records from trusted sources. These records included structured data, such as patient demographics, and unstructured data, like clinical notes. This variety was important to make sure our solution works in real-world situations where data is often messy and divided.
Once we collected the data, we cleaned it. Raw data is rarely ready to use, so we removed duplicates, errors, and unnecessary information. This turned the data into high-quality datasets formatted into JSON Lines (JSONL). This format works well for large-scale annotation and machine-learning systems. Next, we annotated the data. Using the Argilla platform and following PIISA (Personally Identifiable Information Standards for Annotation), we carefully identified and tagged sensitive information. This included direct identifiers like names and medical IDs, as well as indirect ones, like age, location, and combinations of attributes that could indirectly identify someone. This careful annotation ensures that future machine-learning models can correctly tell sensitive data apart from non-sensitive data.
Finally, we focused on validation and scalability. Ensuring quality was very important at this stage. We double-checked our annotations through detailed reviews and designed workflows to handle large amounts of data smoothly. This made our approach both reliable and suitable for larger datasets.
The results of our project provide the foundation for a future where healthcare data privacy is taken seriously. Our curated dataset, with nearly 500,000 records, is ready to train advanced PII detection systems. By developing a universal annotation method, we have improved the accuracy and flexibility of these systems. Also, our partnership with PIISA helps grow its database and sets a higher standard for healthcare privacy.
As healthcare becomes more digital, protecting patient data is more important than ever. Our project shows that privacy is not just a technical issue; it’s about ethics and trust. By designing privacy measures from the beginning, we enable healthcare providers to use big data safely. This is just the first step. Next, we will create and test privacy-preserving technologies using this dataset. Together, we can make a future where healthcare stays safe, ethical, and forward-looking. Protecting healthcare data is not just about technology; it’s about protecting lives.
For more information about PIISA please contact hessiej1228@gmail.com